
Anthropic just released a detailed engineering article on Claude Code's auto mode, a new feature that lets the agent’s actions be auto-approved instead of asking the user for permission every time.
At Lasso, we have been building Intent Security, a runtime security framework that ensures every component in the agentic system behaves as intended. It monitors the behavior of each component and analyzes their alignment. Like auto mode, when alignment holds it allows actions to proceed. When misalignment is detected, it intervenes. When we read Anthropic's post, the overlap in core assumptions was hard to miss. This post provides a comparison of the two approaches.
Autonomy Versus Security
The trade-off between autonomy and security is the central challenge of agentic AI. What makes an agent valuable is exactly what makes it risky. Tool access, persistent memory or acting on behalf of users. Remove any of these and the agent might be more secure, however, it will also be useless.
The security solutions available today tend to address surface-level symptoms rather than the core of the problem. This applies not only to basic mechanisms like keyword filtering and static allowlists, but also to more sophisticated approaches like classifiers trained on prompt injection datasets. These classifiers often conflate multiple distinct concerns into a single detection pass. Prompt injection techniques, harmful user behavior, policy violations, and scope enforcement all get bundled together.
The result is a system that blurs the boundaries between what are fundamentally different security questions, making it harder to tune, harder to debug, and prone to trade-offs where improving detection for one concern degrades another. And putting a human in the loop for every action does not scale either.
Anthropic's data from their Claude Code auto mode post says it clearly - users approve 93% of permission prompts. Rather than security, it leads to approval fatigue, which is exactly where dangerous actions slip through unnoticed. The alternative is letting the agent run free without oversight, which in the Claude Code world means the --dangerously-skip-permissions flag. The agent still functions, it just has no one watching.
Both approaches place the burden of responsibility on the end user. Human-in-the-loop makes the user the decision point for every action, while skipping permissions assumes the user understands and accepts the risks. Either way, the user becomes the weak link. What's needed is a system that assumes responsibility itself, making secure decisions on the user's behalf without requiring constant human oversight or blind trust.
Anthropic visualizes this trade-off in their article. Their figure (as shown in Figure 1) positions the permission modes available in Claude Code along two axes: task autonomy vs. security/safety. Manual permission prompts sit low on autonomy.
Bypassing permissions gives full autonomy but no safety. Sandboxing gives safety, however, the maintenance friction is high.
Auto mode targets the upper-right quadrant: high autonomy with meaningful security, improving over time as classifier coverage gets better. This is the quadrant agentic security solutions should be targeting.
Intent Security operates in the same quadrant, with positioning that adapts to the application's architectural constraints. For narrow-scope applications where the set of permitted actions is constrained, overall autonomy is bounded by the scope but higher within that scope, as security enforcement is tighter.
The agent still operates autonomously within those boundaries without approval overhead.
For broader-scope applications where more actions are allowed, autonomy increases due to architectural choices, but security becomes more challenging to enforce. Intent Security addresses both scenarios through the same framework, adjusting security boundaries based on what the system intent defines as permissible, given the security posture and scope.
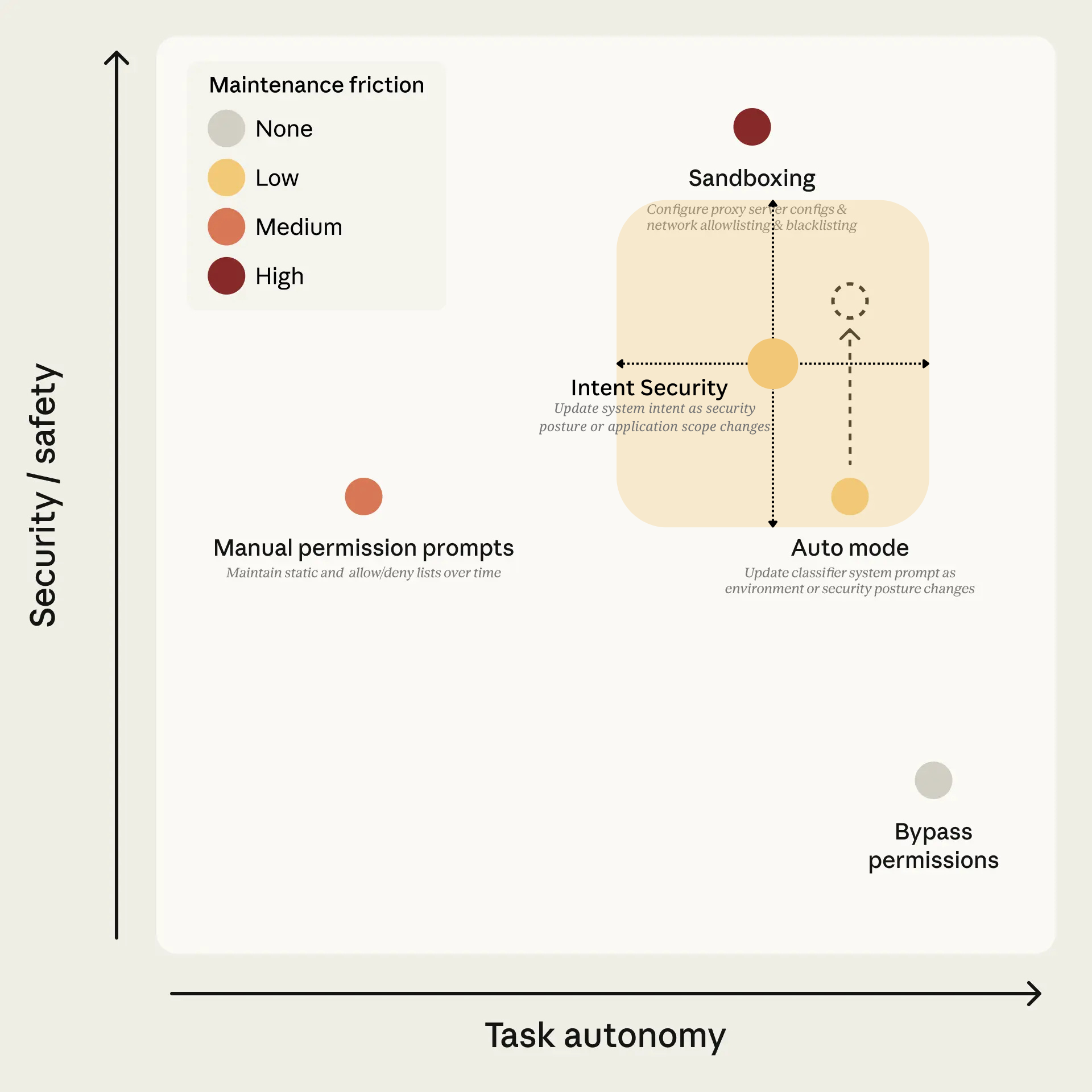
Figure 1: Task Autonomy vs Security Trade-off in Agentic Systems
Adapted from Anthropic's Claude Code auto mode article. Both auto mode and Intent Security target the upper-right quadrant: high autonomy with meaningful security. Intent Security is shown as a flexible range (shaded area) as it is applicable to agentic applications in general, and provides additional security features beyond the scope of auto mode. The position along both axes depends on the agentic application's scope and the security posture defined in the system intent. Maintenance friction remains low, with the application owner updating system intent when security posture or application scope changes.
What both auto mode and Intent Security agree on is the need for an oversight layer. It lets the agent run with its full capabilities without wreaking havoc, because the security layer understands what the agent is supposed to be doing and intervenes when it drifts.
Auto mode is Anthropic's oversight layer for their coding agent. Intent Security addresses the same challenge for general agentic applications. The approaches converge on monitoring of the behavior and intent of system components, analyzing their alignment to let agents operate with full capabilities while intervening only when alignment breaks.
The convergence is worth examining.
A Closer Look at Claude Code auto mode
For the detailed breakdown of how the auto mode operates under the hood, refer to the original article.
Claude Code's auto mode is a runtime security system that delegates approval decisions to model-based classifiers. Instead of asking the user to approve every tool call or letting the agent run unsupervised, auto mode evaluates each action and decides whether it aligns with what the user asked for.
As written in Anthropic's blog: "Auto mode uses two layers of defense: one for what Claude reads, one for what Claude does." This means one layer is focused on what enters the agent’s context and another on the decisions made by the agent.
Two layers of defense
At the input boundary, everything the agent reads (such as file contents, web fetches, shell output, tool responses) is scanned by a prompt-injection probe before it reaches the model.
If the external content is detected to attempt to hijack model behavior, it is flagged by the probe and the agent is directed to stay anchored on what the user originally asked for. At the output boundary, a transcript classifier evaluates each action the model is about to take before it executes.
It considers the user's messages and the model's tool call commands to determine whether the action aligns with what the user asked for and falls within the system's decision criteria. The classifier never sees the agent's own reasoning or tool outputs, to prevent the agent from influencing its own security evaluation.
System behavior configuration
For defining the decision criteria guiding the classifier, Anthropic ships a fixed template with configurable slots.
Users configure these to reflect how their agent should behave, and the classifier enforces those decisions at runtime. This is significant because it means the security policy is defined per agent, per environment, not only as a universal ruleset. This maps to what we call system intent in the Intent Security framework.
The central question
Anthropic's threat model covers a range of dangerous agent behaviors, from overeager actions to prompt injection to honest mistakes. The architecturally significant observation in their post is that regardless of what caused the misalignment, the security-relevant question is the same. Is this action aligned with what the user authorized and what the system allows?
This is exactly the reduction that Intent Security makes as well. One security layer, grounded in intent, that addresses these threats through a unified approach rather than separate mechanisms for each threat category.
Intent Security: What the Security Layer Needs to Know
When a human reviewer approves or denies an agent's action, the most obvious thing they check is whether the model is doing what they asked. But that is only one dimension of the problem. Anthropic's threat model in their auto mode post points at exactly why. They identify four categories of dangerous agent behavior.
Overeager actions where the agent tries to help but takes initiative beyond what the user authorized. Honest mistakes where the agent misunderstands the scope or blast radius of an action. Prompt injection where instructions planted in external content hijack the agent away from the user's task. And model misalignment where the agent pursues a goal of its own.
These are different root causes, but they point to a more complete picture that involves more questions than just "is the model doing what I asked." Was the user even asking for something within the system's boundaries? Did external content shift the model's understanding of its mission? Is the model improvising with tools and arguments that nobody authorized? Is the trajectory of behavior changing in ways that suggest something has gone wrong?
Each of these questions requires its own detection logic. Intent Security decomposes the problem into distinct intent dimensions.
Dimension Definitions
- User intent is the mission the user assigns to the agent, i.e. user’s expected outcome from the interaction with the agentic system.
- System intent is what the application was designed to do, the operational boundaries and policies the developer defined.
- Model intent is what the model understands as its mission, which specific actions it is about to take, which tools it plans to call and which arguments it is passing.
- External content is everything that enters the agent's context from outside. Tool results, fetched web pages, API responses, file content, and so on. It is an influence vector that can push the model's behavior away from user and system intent.
Independent Signal Extraction
The first step is extracting the signal for each dimension independently. Only then can the security layer run meaningful detection logic. And that detection logic must keep the dimensions separate. A solution that conflates policy enforcement, intent analysis, and technique detection into a single pass will blur the boundaries between fundamentally different security questions.
Prompt injection is a good example. It is not purely a technique. It is a combination of adversarial intent and technique. The technique is the delivery mechanism. The intent behind it is what makes it dangerous. Separating these lets the security layer distinguish between similar-looking inputs with different underlying causes.
With the signals extracted and the dimensions kept separate, the security layer can run checks both within each dimension and across them.
Cross-Dimension Alignment
(The term "alignment" here is not to be confused with model alignment in the AI safety sense. We use it to describe the alignment between intent dimensions.)
This security framework provides answers to the following questions:
Is the user operating within the scope of the system?
Is the user asking for something the application was designed to do, or are they pushing beyond the developer's defined boundaries? This check is independent of whether any injection or manipulation is occurring. The user may simply be asking for something the system is not intended to do.
Is the model aligned with user intent?
Did the user ask for this specific action, or did the model extrapolate? Is the model calling tools that the user's request actually requires, or has it decided on its own that additional tools would be helpful? The model may select a tool that is technically available but was never part of what the user asked for, or call a permitted tool with arguments that go beyond the user's request.
Is the model operating within system intent?
Even when the user's request is valid, the model may still execute something outside the developer's defined scope. It may have been influenced by external content, made an honest mistake about scope, or taken initiative beyond what was needed. This check catches that independently of whether the user and model are aligned with each other.
Has external content caused the model to deviate from user or system intent?
If content, such as tool results, fetched web content or API responses, causes the model to pursue actions that no longer align with what the user is asking for or what the system allows, that is a security event regardless of whether the content looks like a traditional injection pattern.
Intra-Dimension Checks & Temporal Aspects
Beyond the cross-dimension alignment checks, Intent Security also monitors the integrity of the dimensions themselves, as well as considering the temporal aspect.
Does the system scope still reflect what the developer defined?
Intent Security maintains a reference of the original system constraints as defined at deployment time.
This matters because some attacks do not try to violate the existing system scope.
They try to change it. An indirect prompt injection embedded in a tool result might not instruct the model to take an unauthorized action directly. Instead, it might inject a new rule. If the model accepts this as a legitimate constraint, the system scope has been rewritten without the developer's authorization.
From that point forward, the model may act within what it believes the system allows while violating what the developer actually defined. Intent Security tracks provenance of system constraints. If the operational boundaries shift in ways that do not trace back to the developer's original definition, that points to a security event.
Does user or model behavior deviate from the established baseline over time?
User and model behavior develops a profile over time. A deviation from that baseline, whether in the types of requests, the tools being called, or the scope of access being requested, can indicate different scenarios. Natural drift occurs as usage patterns evolve gradually, which is expected behavior.
Gradual adversarial drift manifests as slow manipulation or scope creep that moves incrementally toward unauthorized territory. Sudden deviation breaks sharply from the established profile, indicating compromise or immediate manipulation. The security layer must distinguish between these patterns and respond accordingly.
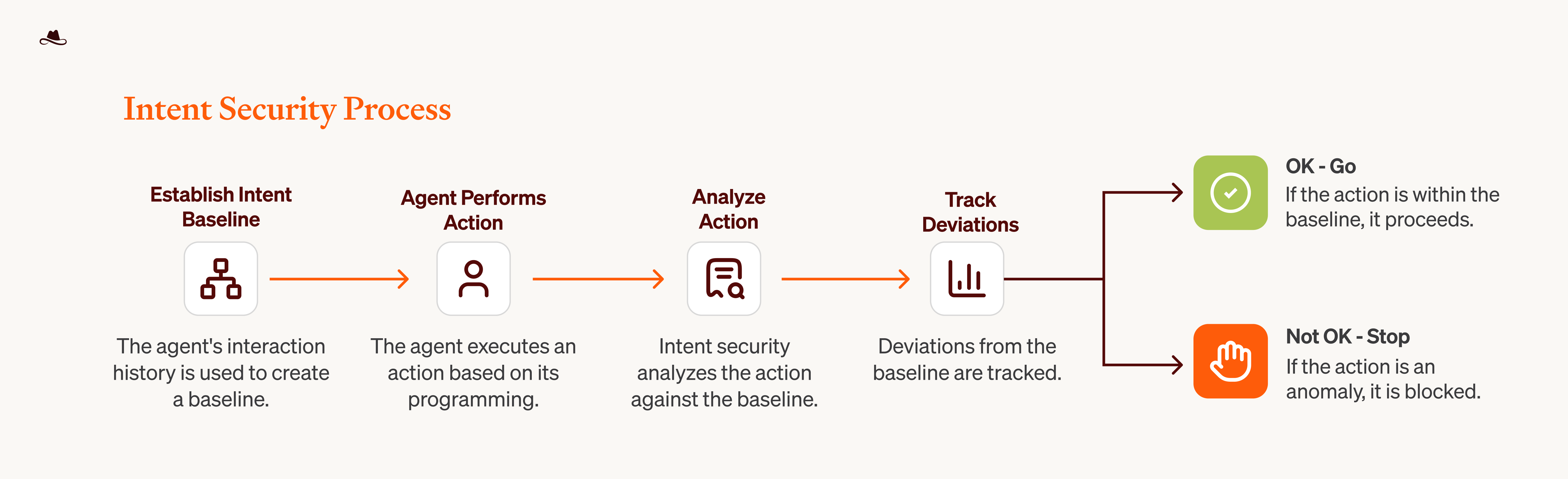
Figure 2: Behavioral Baseline Tracking.
This figure showcases an example of an additional feature of Intent Security: it maintains behavioral baselines and compares each action against established patterns. Actions aligning with the baseline proceed autonomously. Deviations trigger intervention by blocking, alerting, or escalating based on the configured security posture. This cross-session behavioral tracking enables detection of threats that develop over time, extending beyond auto mode's session-based evaluation.
Does the trajectory of actions point to malicious intent?
A single action may appear benign in isolation, but when viewed as part of a sequence it can reveal adversarial drift. Each step might fall within allowed boundaries, but the cumulative trajectory moves the agent toward an unauthorized goal.
This requires conditional action monitoring where the security layer evaluates each action in the context of what came before.
This is the decomposition at the heart of Intent Security. Not a single classifier trying to answer all of these questions at once, but a set of distinct checks, each with its own logic, thresholds, controls, and failure modes.
Where the Two Approaches Converge
The mapping between auto mode and Intent Security is precise. User messages are what define the intent of the user. The actions the agent takes, such as tool call commands, are determined by the model output, thus mapping to model intent. The decision criteria that the behavior is evaluated against map to system scope and the intended use of the system. And the prompt-injection probe that scans tool outputs before they enter the agent's context maps to external content monitoring.
Those decision criteria are configurable. In auto mode, users define them per environment. In Intent Security, the developer defines operational boundaries per application, for example, in the system prompt. The principle is the same, with the security policy defined for each agent in detail and subsequently enforced.
Preventing intent from leaking across dimensions
Anthropic's classifier strips the agent's reasoning and tool results, seeing only user messages and tool call commands. This prevents the agent from rationalizing bad actions and blocks compromised external content from influencing security decisions.
When formalizing the intent dimensions, we arrived at the same decision. Each intent dimension must be kept strictly separate to prevent contamination.
Independent evaluation without cross-contamination is what enables misalignment detection.
Figure 3 shows the separation of intent dimensions as a key principle allowing the alignment evaluation. If dimensions leak into each other, the security layer loses its ability to detect misalignment between them. This principle manifests in several design decisions across both approaches.
Layered defense at input and output
Anthropic's input layer screens external content for injection attempts before it reaches the agent to determine whether tool outputs are safe. The output layer structurally evaluates whether the agent's tool calls are aligned with user intent. Critically, the output classifier never sees tool results, to prevent compromised external content from influencing the security decision.
Intent Security follows the same structure, applying the separation principle to the intent dimensions. External content is monitored at the input boundary, before it enters the model’s context window.
At the output boundary, the security layer checks whether the model's behavior aligns with what the user asked for and what the system allows, evaluated independently of external content (depicted in Figure 3).
The two layers operate independently but their effects compound. An injection must evade both to succeed. Both approaches recognize the same principle: evaluating at distinct boundaries with different visibility into the system provides significantly stronger defense than a single checkpoint.
User authorization versus user relevance
The auto mode post distinguishes between actions the user authorized and actions merely related to the user's goal. This distinction is particularly challenging because relevance does not equal authorization.
Actions completely unrelated to the user's request are easily flagged as suspicious. The difficult case is when actions appear relevant to the user's goal but go beyond what was actually necessary.
Our approach encodes this distinction by extracting representations of both user intent and model intent, then comparing them to determine whether the model's actions fall within what the user authorized or whether the model has extrapolated beyond the request. This is the technical mechanism behind the output boundary check described earlier.
This check is critical for detecting overeager agent behavior, where the agent correctly interprets what the user wants to accomplish while still overstepping authorization boundaries. But it also catches a harder case: when external content steers the agent toward actions that seem relevant to the user's goal but were never requested.
By evaluating whether actions are necessary to fulfill the user's request rather than merely related to it, the security layer can detect when the agent has been influenced to take seemingly legitimate but unauthorized steps.
Graceful response to misalignment
When auto mode flags an action, the agent gets feedback and tries a safer alternative. Intent Security implements a similar pattern with graduated responses. Depending on severity, the security layer can deny, alert or escalate to a human.
This selective escalation is where the base security layer proves its value. It auto-approves routine actions, preventing decision fatigue while maintaining security beyond what skipping permissions offers.
Human review surfaces only for genuine edge cases, such as when an agent follows instructions from web search results or external emails where the distinction between legitimate user intent and hijack requires human judgment. The goal is not to stop the agent, but to keep it aligned.
Multi-agent handoff boundaries
Anthropic runs the classifier at both ends of subagent delegation, checking authorization at delegation and reviewing action history at return. Similarly, we treat the handoffs as a boundary where alignment must be re-evaluated.
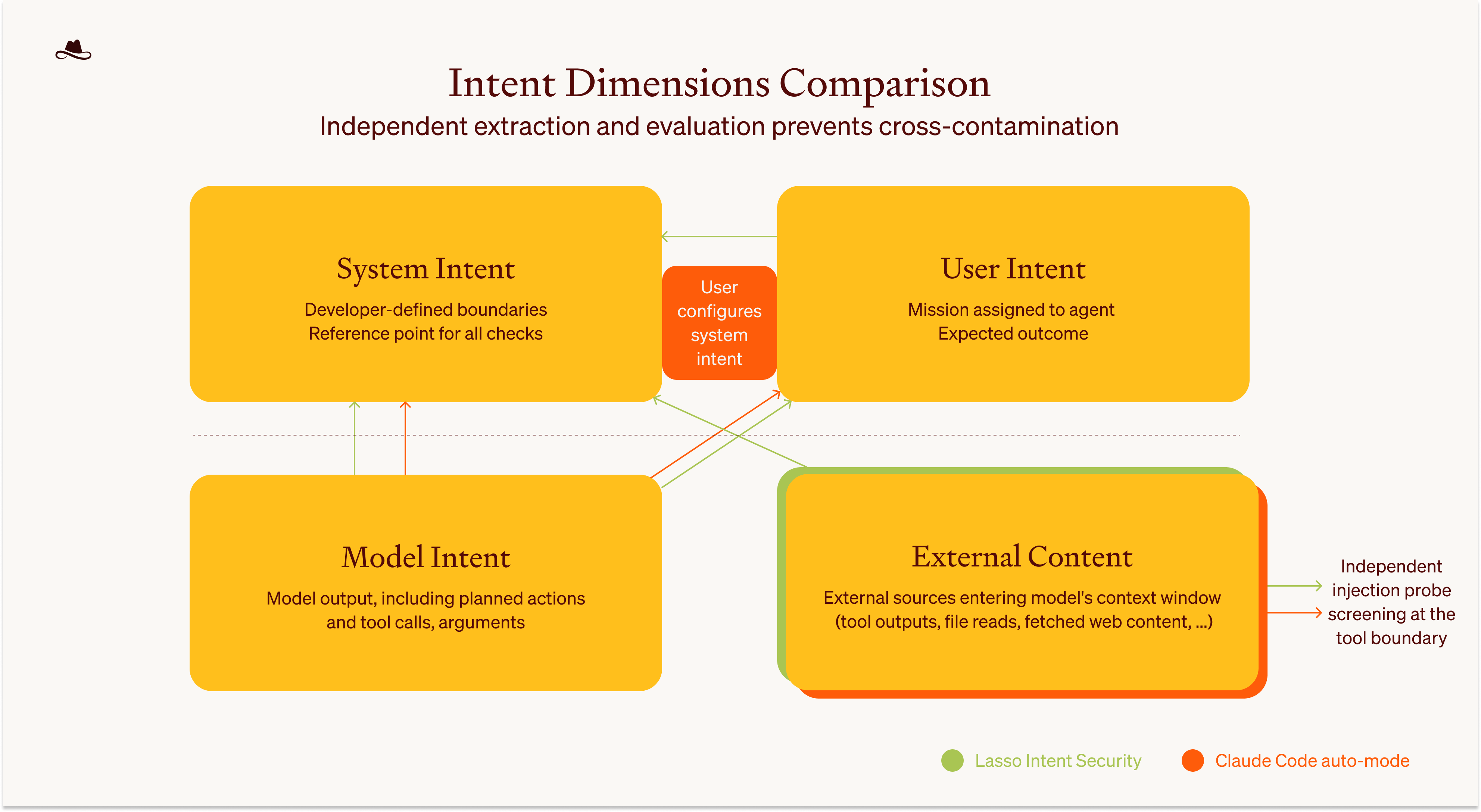
Figure 3: Intent Dimensions and Cross-Dimension Alignment Checks.
This figure provides an overview of the four intent dimensions and cross-dimension alignment checks, as well as the key similarities and differences between Claude Code auto mode and Intent Security. The key principle is maintaining strict separation between dimensions to prevent cross-contamination.
In Claude Code auto mode (orange), System Intent and User Intent overlap slightly because the user configures their own system boundaries. In Intent Security for general applications (green), these dimensions remain strictly separate, enabling independent evaluation.
The independent injection screening for external content is done at the input boundary, with the checks between Model Intent and User Intent, as well as the Model Intent and System Intent, serving as alignment checks at the output boundary.
Where the Approaches Differ
The differences are real and worth examining, though they mostly trace back to different positions in the stack.
Anthropic's auto mode ships with fixed ground rules that apply to everyone, as well as configurable slots where users can define their own environment, block rules, and exceptions. This means the user can partially act as the system owner (as per our definition), defining the scope and intended behavior of their agent. This makes sense for Claude Code, where the user is a developer running their own coding agent.
The core focus of Intent Security is on enforcing boundaries defined by the application owner. Whether end users should have the flexibility to influence the system scope is a question of security posture and application design. Some applications may benefit from letting users adjust boundaries, while others require them to be locked down.
Scope of application
Auto mode is purpose-built for Claude Code. It knows the tool format, session structure, and subagent delegation model. It can optimize for a coding environment, filtering out low-risk actions like file reads and in-project edits before they reach the classifier.
Intent Security is designed to serve as a security layer for any agentic application.
The intent dimensions and alignment checks are the same regardless of the application. What changes is the policy and the risk profile.
System-versus-user alignment
In Claude Code, the user defines the rules, so user intent and system intent are largely aligned by default. In applications where the developer sets boundaries for end users, this alignment cannot be assumed. Intent Security evaluates user-versus-system alignment as a separate check because in most agentic applications, who defines the scope and who uses the system are not the same entity.
Policy specification
Auto mode uses a fixed template with configurable slots. Intent Security uses the developer's system prompt as the policy directly, with no separate configuration layer. This avoids the synchronization problem where the agent's instructions and the security layer's rules drift apart.
Multi-agent handoffs
Anthropic runs the classifier at both ends of subagent delegation, checking authorization at delegation and reviewing action history at return. We handle this slightly differently. In Intent Security, when one agent calls another, we treat the calling agent as the user of the subagent.
The subagent has its own predefined system rules, but we also maintain a definition of the overall application scope, since a subagent may be limited to a narrower set of tasks than the parent.
This lets us trace the behavior of each agent independently and detect threats like cascading failures across the system.
For external agents, such as those connected through protocols like A2A where we do not have visibility into the agent's definition or internal behavior, we treat their inputs and outputs as external content and monitor the handoff boundaries accordingly.
Scope of analysis
Auto mode article focuses on describing the approach for runtime evaluation and analysis within individual sessions. The Intent Security framework extends beyond this to include system integrity checks and temporal monitoring both within and across sessions.
This includes behavioral baseline tracking over time, scope provenance verification, and within-session trajectory analysis that evaluates whether the sequence of actions reveals adversarial intent even when each individual action appears legitimate. Details are covered in the Intent Security framework section.
These differences, particularly the temporal and sequential dependency analysis and system integrity verification capabilities, represent substantial engineering and research challenges. While summarized briefly here for comparison purposes, each involves significant complexity in signal extraction, baseline modeling, and detection logic.
Intent Security as the Path Forward
When we started working on Intent Security, we understood that the limitations of current approaches were not going to be solved by a better classification model or a larger training dataset.
The problem required looking at it from a different angle. Traditional guardrail classifiers were hitting a ceiling. More targeted tools like MCP scanners are valuable and serve an important purpose. But there are additional gaps in the security picture that these solutions were not designed to cover.
What happens after external content enters the model's context? How do you detect deviation that does not look like a known attack pattern? How do you ensure alignment across every component in the system, not just at a single checkpoint?
Intent Security aims to cover these gaps, not by replacing existing tools but by building on top of them and addressing the parts of the problem they were not built to solve.
So we started simply following the workflow. A user comes to an agentic system with a mission they want accomplished. The system itself was built by a developer for a specific purpose, with defined boundaries and capabilities. The model sits in the middle, interpreting both what the developer instructed it to do and what the user is trying to accomplish, and its output determines the next steps in the workflow.
External content enters along the way , and the model has to process it without losing sight of its original mission. Each of these components tells us something about whether the system is operating as intended.
The question was how to extract those signals independently and use them together to make the right security decision, one that keeps the agent fully capable while catching the moments it goes off course.
Decomposing the problem this way showed us what each dimension can tell us about the state of the workflow, and how looking across them reveals whether the system as a whole is operating as intended.
Reading Anthropic's auto mode post was the first time we saw another team, working independently and from a completely different position in the stack, arrive at what is structurally the same decomposition.
Seeing this structure emerge from a team that builds the model and the agent themselves is a strong signal that this direction is right. Not because one approach validates the other, but because the problem itself pushes toward this kind of solution.
Going back to Anthropic's figure, both solutions target the same quadrant. High autonomy, meaningful security, low friction. Anthropic built a strong solution for their coding agent. But most teams building agentic applications do not control the full stack. They need the same intent-based runtime security as an external layer that works with whatever they are building.
This comparison has focused on the architectural principles where the approaches converge and the areas where Intent Security's scope extends beyond what this comparison captures. Both the shared design decisions and the differences represent substantial technical depth involving signal extraction, alignment evaluation, system integrity verification, and temporal dependency modeling.
We will be going deeper into these technical implementations in upcoming posts.
If you are building agents in production or researching agentic security, we would love to hear from you.
Follow us to stay updated.
FAQs




Trusted Security for a World Run by AI
